I'm currently working on a side project that I've had in my head for a while.
There are a few blogs and articles out there about measuring and ranking the rhyme styles of different rappers. And while there is nothing wrong with ranking your favorite rappers (I do this from time to time and it's pretty hard), I make no assumption that I can justify those rankings based on a single dimension of the multi-dimensional lyric-space. My intention here isn't to assign hard quantities to different rappers, but to better visualize their styles based on their rhyme patterns.
While other rhyme detection algorithms do a great job of identifying complex rhyming structure and multi-syllabic rhymes to quantify rhyme, my understanding was that the rhyme definitions were somewhat strict. For example, a multi-syllablic rhymes could only be counted as far as the syllable sequences matched almost exactly. If you're a student of lyrics, you might agree that the best rhymes are not always perfect, and many times, out of the context of the backing music and rhythm, they might not appear to be rhymes at all. That is a difficult challenge in detecting lyrical rhymes from text only -- because the meter isn't necessarily strict and there is no direct timing information, it is easy to miss the intended rhyme. One aim here was to also identify these loose rhymes based on the similarity of repeated multi-syllabic patterns within the lyrics.
Also, while data scientists are expected to measure things and deliver new insights based on quantifiable evidence -- that isn't my primary goal here. Again, I am really aiming to complement, visually, rhyme style. My hope is that the styles of different rappers with distinct timing and structure will be evident when represented visually. Measurements might come later when I have more trust in my algorithm and I am genuinely curious about who outranks who -- but in the end art appreciation is highly subjective and I don't wish to reduce it down to my own interpretations reflected in my code. I feel that if I leave this purely as a visual project, then it's somewhat of an art project of my own, which is more fun, and I don't get to do that as much as I'd like.
Finally, I'm not a visual artist (or a computer scientist). I want to make the final product more visually pleasing, but I'm still working on building an understanding of how to plot with Python. I've posted a couple figure results from my code, based on a few bars from some select artists.
Here's a quick rundown of the algorithm:
1) decompose lyrics down to syllables (I limited the text input to 4 bars (16 counts of rhythm))
2) measure how similar every pair of syllables are to each other based on their phonemic representations (vowel sounds, trailing consonants, and stress) and put these relationships in graph form
3) identify communities (or modules) in the graph which indicate syllables that sound most similar to each other
4) represent the lyrics as a sequence of the temporal occurrence of communities
5) cluster together subsequences within the lyrics using k-modes, with the aim that similar multi-syllabic rhyme patterns will cluster together.
So far the algorithm works (kind of). I'll write about the details of its performance later, after I improve it, but for now I'm just going to leave a few pictures so I can feel like I've accomplished something over the last week. Also, please note these images are not near the final product I wish to make. They are only meant to demonstrate that the algorithm CAN detect patterns which align with the rhymes in the lyrics, but at the moment each set of lyrics requires hand-tuning the parameters (length of rhyme pattern, number of clusters to search for, etc.). All this, eventually, I hope will be mostly automated in the future, although I feel I am a long way off still.
A quick explanation of the figures:
- At the top, the input words are shown. Those in orange were clustered together to have the most dominant, similar rhyme pattern (rhyme pattern = temporal syllable sequence).
- The beginning of each word on the top is aligned with the timing of its first syllable. Each syllable is represented by the squares and circles in the plot. They are shown in their temporal order along the x-axis. Their placement on the y-axis is to which syllable community they were assigned through the syllable graph analysis.
- The color and size of the circles indicate the temporal order of the sequence (i.e. the smallest and lightest circle indicate the beginning of a syllable pattern). This was really just for visual effect and I admit the visuals need tweaking -- the order could be indicated simply by size or color alone (or a line). Nonetheless, big circles should rhyme with big circles, and little with little.
- Regarding the comment above, I added an orange line for each syllable sequence to indicate the sequence beginnings and ends.
- Finally, the text on the bottoms are the CMUdict pronunciation of each syllable, with the different colors again aligning with the same colored circle above and emphasizing the order of the syllable sequence.
(Note: please forgive me if the lyrics are incorrect -- I pulled them from Genius and although I think they are right I'm not 100% sure)
Of course, my first example is the one that worked best, from Gift of Gab's Protocol (actual dominant rhymes (excluding nested rhymes) (as I hear them) are in bold):
"you know diddly squat / I know rhythm it's like I'm Bo Diddley / rock n' roll history stocked in your memory / box your flow, it'll be chopped / and whole cities and blocks'll go instantly nuts"
 You can see that the all the rhyme patterns were detected, and visually they are very similar but not identical. The last word, "nuts" isn't even a slant rhyme with "squat", "rock", "stocked", etc. -- nonetheless the pattern was detected to be similar enough to the others and was counted as a rhyme. Again, I want to emphasize that one of my main goals here is to detect these rhyme patterns that aren't exactly matching the others.
You can see that the all the rhyme patterns were detected, and visually they are very similar but not identical. The last word, "nuts" isn't even a slant rhyme with "squat", "rock", "stocked", etc. -- nonetheless the pattern was detected to be similar enough to the others and was counted as a rhyme. Again, I want to emphasize that one of my main goals here is to detect these rhyme patterns that aren't exactly matching the others.
Not all rhyme patters are detected, though. Here is where the algorithm got only 7 out of 9 rhymes in Edan's Syllable Practice:
"syllable practice is never a task / clever attacks left competitors waxed / steady get laxed / so I fed 'em a fax / telling 'em facts / propelling repetitive tracks and feminine raps to the kennel for snacks"
 The reason "competitors waxed" and "repetitive tracks" were not detected here is because a current constriction for rhyme patters is that they have to be composed of full words. In this case, the algorithm was looking for 4-syllable rhyme patters, and these 2 cases have 5 syllables. This is a pretty serious limitation of the current algorithm as rhymes beginning or ending with only parts of words is pretty common.
The reason "competitors waxed" and "repetitive tracks" were not detected here is because a current constriction for rhyme patters is that they have to be composed of full words. In this case, the algorithm was looking for 4-syllable rhyme patters, and these 2 cases have 5 syllables. This is a pretty serious limitation of the current algorithm as rhymes beginning or ending with only parts of words is pretty common.
The algorithm also picks up a lot of false positives (it clusters non-rhyme patterns with rhymes) at the moment. For example, here's 4 bars from Yassin Bey's (Mos Def) Brooklyn:
"Brooklyn my habitat / the place where it happen at / live sway and the sharp balance of the battle axe / irons is brandished at / thugs draw they hammers back / it's where you find the News 2 crew cameras at"
 Here it picked up 5 of the 6 rhymes, but also added 4 rhyme sequences that aren't really there. Additionally, the last reported sequence overlaps with the second to last. I'm working on this problem by throwing out overlapping rhyme sequences within a cluster, and hope to have updates in the near future.
Here it picked up 5 of the 6 rhymes, but also added 4 rhyme sequences that aren't really there. Additionally, the last reported sequence overlaps with the second to last. I'm working on this problem by throwing out overlapping rhyme sequences within a cluster, and hope to have updates in the near future.
Another example of false positives is in Killer Mike's Legend Has It:
"we are the murderous pair / that went to jail and we murdered the murderers there / then went to hell and discovered the devil delivered some hurt and despair"
 You can even see, clearly, how the false positive doesn't even look at all like the dominant rhymes. I'm not sure why this was picked up, but k-modes clustering is stochastic and as I mentioned I'm working on a way to refine the identified clusters and reduce the chance of detecting these non-rhymes.
You can even see, clearly, how the false positive doesn't even look at all like the dominant rhymes. I'm not sure why this was picked up, but k-modes clustering is stochastic and as I mentioned I'm working on a way to refine the identified clusters and reduce the chance of detecting these non-rhymes.
I'd also like to point out that by looking at the picture above it would appear Killer Mike doesn't rhyme as well as some of the others I've posted -- in my own opinion this is not true and is exactly the type of conclusion I'd like to avoid in this project, which is visually to enhance the appreciation of rhyme styles between artists, not necessarily to rank them. It's important to remember that the algorithm is limited by the information available and my own interpretations of rhyme patterns (which should not necessarily be the same as yours).
And I have to add my (probably, although it's hard to choose) favorite rapper here. Of the few artists I've tested so far, the most troublesome is Aesop Rock, also recently shown to have the most expansive vocabulary in his rhymes. Here's a few bars from Shrunk:
"you pack up all your manias / you're sitting in a waiting room / you're dreaming of arcadia / you're feeling like a baby tooth / awaiting panacea channeling your inner beowulf / in purgatory just before you pay up to filet yourself"

If you just read the lyrics above, you can tell that these are pretty loose rhymes (but again with the musical backing the rhymes are less questionable). The algorithm detected 4 of the 6 rhyme patterns, and reported 2 additional ones that I don't hear (and don't really exist), one of which overlaps with another.
Finally, as a control I've added part of a 2013 commencement speech from Steven Colbert:
"And you know this is an impressive institution because it rejected my application. Apparently the admission board took issue with the content of my essay, which was none, because I never sent it."
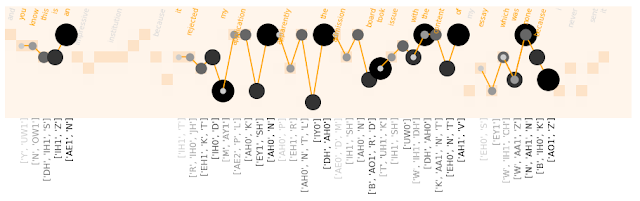 Clearly here, the patterns identified are not rhymes, and there are many overlaps of patterns. Because k-modes clustering will always cluster patterns together, no matter how different they are, the output here can be considered noise (I plan on implementing some thresholding to prevent this kind of noisy output).
Clearly here, the patterns identified are not rhymes, and there are many overlaps of patterns. Because k-modes clustering will always cluster patterns together, no matter how different they are, the output here can be considered noise (I plan on implementing some thresholding to prevent this kind of noisy output).
Overall, the algorithm is far from perfect, but it seems it's a good start.
Here's where I hope to go with it, after improving my current code:
1) Not limit the input to 4 bars, but rather an entire song, or collection of songs.
2) Detect nested rhyme patterns within main rhymes.
3) Have a better representation on the rhythm of stressed syllables, which are key to identifying the signature cadence of artists.
4) Somehow incorporate semantic information in the finished visuals.
5) Assign non-arbitrary values to the syllable sequences, which will enable a better tracking of how rhyme patterns change within a song.
6) Create more appealing and meaningful final visuals, which are distinct (and truly representative) for each artist.
I also realize the best input would actually be the stems of the vocals themselves, where the lyrics could be transcribed automatically, and the timing and tone would be available. That is something I've been keeping in mind for the far distant future.
There are a few blogs and articles out there about measuring and ranking the rhyme styles of different rappers. And while there is nothing wrong with ranking your favorite rappers (I do this from time to time and it's pretty hard), I make no assumption that I can justify those rankings based on a single dimension of the multi-dimensional lyric-space. My intention here isn't to assign hard quantities to different rappers, but to better visualize their styles based on their rhyme patterns.
While other rhyme detection algorithms do a great job of identifying complex rhyming structure and multi-syllabic rhymes to quantify rhyme, my understanding was that the rhyme definitions were somewhat strict. For example, a multi-syllablic rhymes could only be counted as far as the syllable sequences matched almost exactly. If you're a student of lyrics, you might agree that the best rhymes are not always perfect, and many times, out of the context of the backing music and rhythm, they might not appear to be rhymes at all. That is a difficult challenge in detecting lyrical rhymes from text only -- because the meter isn't necessarily strict and there is no direct timing information, it is easy to miss the intended rhyme. One aim here was to also identify these loose rhymes based on the similarity of repeated multi-syllabic patterns within the lyrics.
Also, while data scientists are expected to measure things and deliver new insights based on quantifiable evidence -- that isn't my primary goal here. Again, I am really aiming to complement, visually, rhyme style. My hope is that the styles of different rappers with distinct timing and structure will be evident when represented visually. Measurements might come later when I have more trust in my algorithm and I am genuinely curious about who outranks who -- but in the end art appreciation is highly subjective and I don't wish to reduce it down to my own interpretations reflected in my code. I feel that if I leave this purely as a visual project, then it's somewhat of an art project of my own, which is more fun, and I don't get to do that as much as I'd like.
Finally, I'm not a visual artist (or a computer scientist). I want to make the final product more visually pleasing, but I'm still working on building an understanding of how to plot with Python. I've posted a couple figure results from my code, based on a few bars from some select artists.
Here's a quick rundown of the algorithm:
1) decompose lyrics down to syllables (I limited the text input to 4 bars (16 counts of rhythm))
2) measure how similar every pair of syllables are to each other based on their phonemic representations (vowel sounds, trailing consonants, and stress) and put these relationships in graph form
3) identify communities (or modules) in the graph which indicate syllables that sound most similar to each other
4) represent the lyrics as a sequence of the temporal occurrence of communities
5) cluster together subsequences within the lyrics using k-modes, with the aim that similar multi-syllabic rhyme patterns will cluster together.
So far the algorithm works (kind of). I'll write about the details of its performance later, after I improve it, but for now I'm just going to leave a few pictures so I can feel like I've accomplished something over the last week. Also, please note these images are not near the final product I wish to make. They are only meant to demonstrate that the algorithm CAN detect patterns which align with the rhymes in the lyrics, but at the moment each set of lyrics requires hand-tuning the parameters (length of rhyme pattern, number of clusters to search for, etc.). All this, eventually, I hope will be mostly automated in the future, although I feel I am a long way off still.
A quick explanation of the figures:
- At the top, the input words are shown. Those in orange were clustered together to have the most dominant, similar rhyme pattern (rhyme pattern = temporal syllable sequence).
- The beginning of each word on the top is aligned with the timing of its first syllable. Each syllable is represented by the squares and circles in the plot. They are shown in their temporal order along the x-axis. Their placement on the y-axis is to which syllable community they were assigned through the syllable graph analysis.
- The color and size of the circles indicate the temporal order of the sequence (i.e. the smallest and lightest circle indicate the beginning of a syllable pattern). This was really just for visual effect and I admit the visuals need tweaking -- the order could be indicated simply by size or color alone (or a line). Nonetheless, big circles should rhyme with big circles, and little with little.
- Regarding the comment above, I added an orange line for each syllable sequence to indicate the sequence beginnings and ends.
- Finally, the text on the bottoms are the CMUdict pronunciation of each syllable, with the different colors again aligning with the same colored circle above and emphasizing the order of the syllable sequence.
(Note: please forgive me if the lyrics are incorrect -- I pulled them from Genius and although I think they are right I'm not 100% sure)
Of course, my first example is the one that worked best, from Gift of Gab's Protocol (actual dominant rhymes (excluding nested rhymes) (as I hear them) are in bold):
"you know diddly squat / I know rhythm it's like I'm Bo Diddley / rock n' roll history stocked in your memory / box your flow, it'll be chopped / and whole cities and blocks'll go instantly nuts"

Not all rhyme patters are detected, though. Here is where the algorithm got only 7 out of 9 rhymes in Edan's Syllable Practice:
"syllable practice is never a task / clever attacks left competitors waxed / steady get laxed / so I fed 'em a fax / telling 'em facts / propelling repetitive tracks and feminine raps to the kennel for snacks"

The algorithm also picks up a lot of false positives (it clusters non-rhyme patterns with rhymes) at the moment. For example, here's 4 bars from Yassin Bey's (Mos Def) Brooklyn:
"Brooklyn my habitat / the place where it happen at / live sway and the sharp balance of the battle axe / irons is brandished at / thugs draw they hammers back / it's where you find the News 2 crew cameras at"

Another example of false positives is in Killer Mike's Legend Has It:
"we are the murderous pair / that went to jail and we murdered the murderers there / then went to hell and discovered the devil delivered some hurt and despair"

I'd also like to point out that by looking at the picture above it would appear Killer Mike doesn't rhyme as well as some of the others I've posted -- in my own opinion this is not true and is exactly the type of conclusion I'd like to avoid in this project, which is visually to enhance the appreciation of rhyme styles between artists, not necessarily to rank them. It's important to remember that the algorithm is limited by the information available and my own interpretations of rhyme patterns (which should not necessarily be the same as yours).
And I have to add my (probably, although it's hard to choose) favorite rapper here. Of the few artists I've tested so far, the most troublesome is Aesop Rock, also recently shown to have the most expansive vocabulary in his rhymes. Here's a few bars from Shrunk:
"you pack up all your manias / you're sitting in a waiting room / you're dreaming of arcadia / you're feeling like a baby tooth / awaiting panacea channeling your inner beowulf / in purgatory just before you pay up to filet yourself"

If you just read the lyrics above, you can tell that these are pretty loose rhymes (but again with the musical backing the rhymes are less questionable). The algorithm detected 4 of the 6 rhyme patterns, and reported 2 additional ones that I don't hear (and don't really exist), one of which overlaps with another.
Finally, as a control I've added part of a 2013 commencement speech from Steven Colbert:
"And you know this is an impressive institution because it rejected my application. Apparently the admission board took issue with the content of my essay, which was none, because I never sent it."

Overall, the algorithm is far from perfect, but it seems it's a good start.
Here's where I hope to go with it, after improving my current code:
1) Not limit the input to 4 bars, but rather an entire song, or collection of songs.
2) Detect nested rhyme patterns within main rhymes.
3) Have a better representation on the rhythm of stressed syllables, which are key to identifying the signature cadence of artists.
4) Somehow incorporate semantic information in the finished visuals.
5) Assign non-arbitrary values to the syllable sequences, which will enable a better tracking of how rhyme patterns change within a song.
6) Create more appealing and meaningful final visuals, which are distinct (and truly representative) for each artist.
I also realize the best input would actually be the stems of the vocals themselves, where the lyrics could be transcribed automatically, and the timing and tone would be available. That is something I've been keeping in mind for the far distant future.
Comments
Post a Comment